Publié par Thibaut Malcourant le 18 novembre 2025
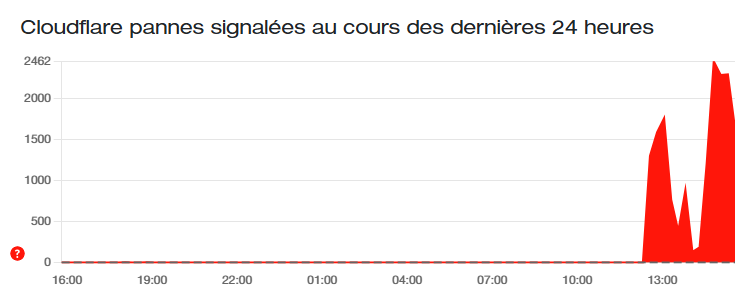
Le mardi 18 novembre 2025 restera gravé comme l’une des journées les plus perturbatrices de l’histoire récente du web. Le géant de l’infrastructure et de la sécurité Internet, Cloudflare, a été frappé par une panne interne massive. Cela a rendu inaccessibles des milliers de sites et de services à travers le globe, impactant directement des millions d’utilisateurs.
🚨 Chronologie et Étendue de l’Incident
La perturbation a commencé en milieu de journée (heure de l’Europe centrale). Les premiers rapports faisant état d’une difficulté à accéder à des plateformes majeures. Cloudflare fournit des services cruciaux tels que la distribution de contenu (CDN), la protection contre les attaques DDoS, et les services DNS. Aussi, il est au cœur de l’architecture moderne du web. Lorsque son service vacille, c’est une large partie de l’Internet qui s’écroule.
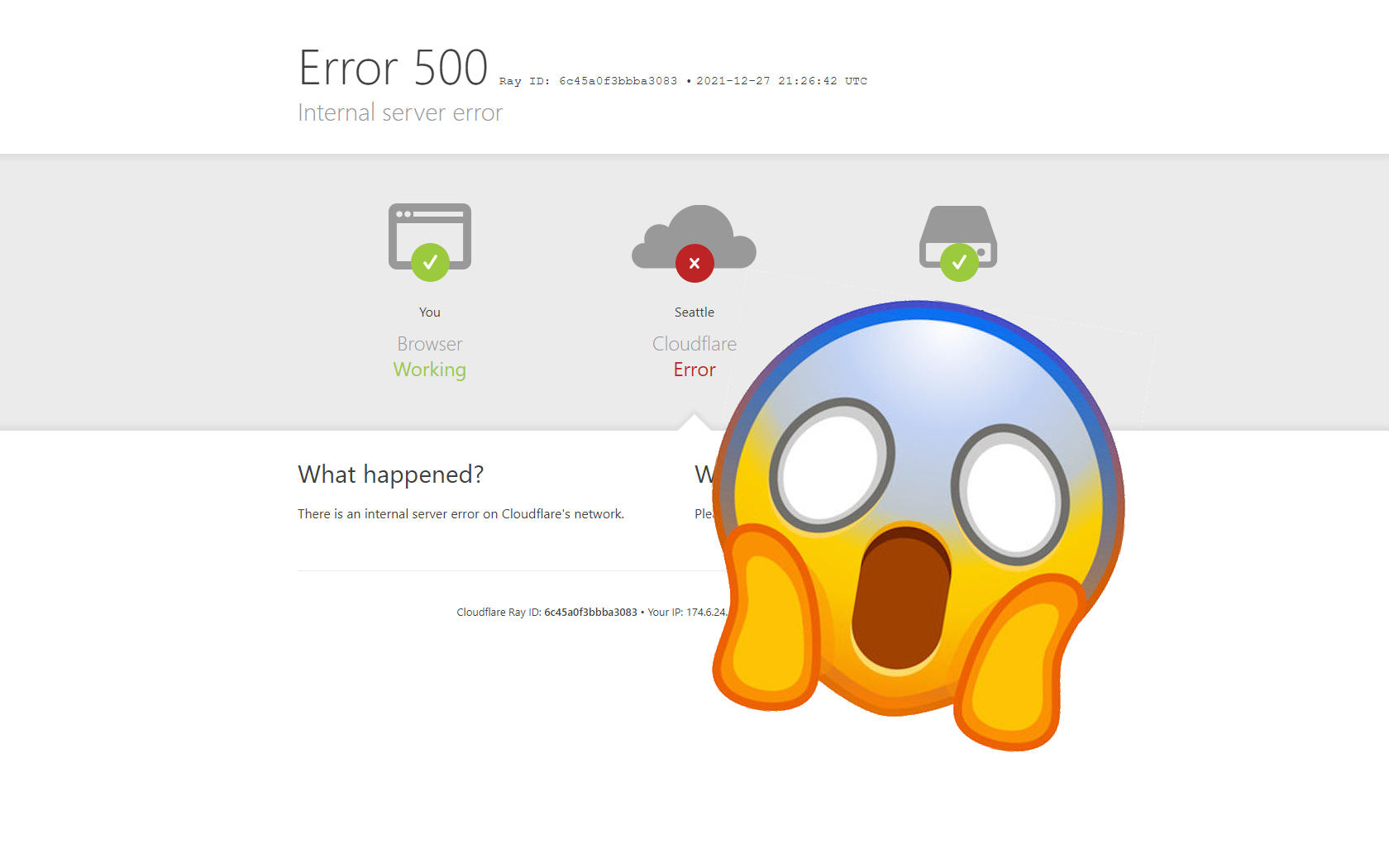
Suite à la panne chez Cloudflare, les utilisateurs et les entreprises ont rapidement été confrontés à une vague d’erreurs HTTP 500 (“Internal Server Error”) ou des messages d’indisponibilité, signifiant que le serveur contacté ne pouvait pas traiter la requête. L’impact a été immédiat et spectaculaire :
- Services d’IA et de Productivité : ChatGPT, Perplexity, et même Gemini ont signalé des interruptions, entravant la productivité de millions de professionnels et d’étudiants.
- Plateformes Sociales et de Divertissement : Le réseau social X (anciennement Twitter) et la plateforme de streaming musical Spotify ont également été touchés.
- Services Gouvernementaux et Financiers : Des portails cruciaux pour l’administration et le commerce électronique ont subi des ralentissements ou des coupures, soulignant la criticité de l’infrastructure.
L’étendue du problème était telle que même Downdetector, le site de référence pour signaler les pannes, a connu des difficultés. Les utilisateurs ne pouvaient donc plus vérifier l’état du réseau.
Et ne croyez pas que seuls certains services internet sont touchés. En effet, cela a par exemple occasionné des retards et des annulations de TGV en France. Certains sites utilisés par tout le monde utilisent aussi Cloudflare et ont été perturbés.
⚙️ Cause de la panne et Réponse Technique de Cloudflare
Contrairement à de nombreuses pannes récentes, Cloudflare a rapidement écarté la piste d’une attaque externe coordonnée (DDoS). Les premières analyses internes ont pointé vers une dégradation de la performance du réseau central (backbone), très probablement déclenchée par une erreur de configuration logicielle ou une mise à jour défectueuse se propageant en cascade à travers les centres de données mondiaux.
Dans un effort pour circonscrire les dégâts, les ingénieurs de Cloudflare ont procédé à des désactivations temporaires de certaines fonctionnalités. Ce fut le cas, par exemple du service WARP à Londres. Cela a permis d’isoler les points de défaillance. Le rétablissement a été progressif. Après plusieurs heures de travail intensif, l’entreprise a déclaré la résolution principale du problème, bien que des taux d’erreur résiduels aient persisté pendant la phase de stabilisation complète.
🔗 Le Spectre de la Dépendance : Cloudflare et AWS
Cette panne remet une fois de plus en lumière la question fondamentale de la centralisation de l’Internet. Une poignée d’entreprises (les fournisseurs de cloud et de CDN) sont les piliers sur lesquels repose la majorité des services numériques. La défaillance de l’un d’entre eux a un effet domino catastrophique.
Cet incident est d’autant plus préoccupant qu’il survient peu de temps après une autre panne majeure. Fin octobre 2025, Amazon Web Services (AWS) – le plus grand fournisseur de cloud computing au monde – a connu une panne significative, principalement dans sa région stratégique us-east-1 (Virginie du Nord). Cette panne, due à des problèmes techniques internes, avait déjà paralysé des milliers d’entreprises et de services en ligne. Cela allait des plateformes de streaming aux outils de travail à distance, et même certains services du quotidien.
La récurrence et la gravité de ces incidents (Cloudflare en novembre, AWS en octobre) soulignent un risque systémique : la résilience du web est directement liée à la fiabilité de ces quelques méga-infrastructures. Les entreprises sont désormais confrontées au défi coûteux de diversifier leurs fournisseurs (multi-cloud ou multi-CDN) pour garantir une véritable continuité de service. Cette diversification doit permettre de fonctionner, même lorsque l’un des piliers technologiques mondiaux s’effondre temporairement. Ces événements sont des rappels brutaux que l’Internet, malgré son apparence robuste, reste un réseau de dépendances interconnectées. Il est ainsi vulnérable aux erreurs humaines ou techniques les plus infimes.
Même si vous n’êtes pas dans le milieu informatique, vous connaissez désormais les noms d’AWS ou Cloudflare.
Voici les principales mesures que les entreprises peuvent prendre pour se prémunir contre la défaillance d’un fournisseur unique d’infrastructure (Single Point of Failure – SPOF) :
🛡️ Stratégies de Résilience Post-Panne
1. Adopter une Architecture Multi-Cloud
Le fait de dépendre d’un seul fournisseur de cloud (comme AWS, Azure ou Google Cloud) est un risque majeur.
- Principe : Distribuer les charges de travail et les données critiques sur au moins deux plateformes cloud distinctes et indépendantes.
- Application : En cas de panne régionale ou globale chez le fournisseur principal, l’entreprise peut basculer rapidement vers l’environnement du fournisseur secondaire. Cela garantit la haute disponibilité.
2. Implémenter le Multi-CDN (Content Delivery Network)
Cloudflare est un CDN, mais il en existe d’autres (Akamai, Fastly, Azure CDN, etc.).
- Principe : Utiliser plusieurs réseaux de diffusion de contenu pour servir le trafic web.
- Application : Si Cloudflare tombe, une partie du trafic (images, vidéos, scripts) est immédiatement servie par un autre CDN. Cela nécessite une couche de “gestion du trafic globale” (Global Traffic Management) pour diriger les requêtes vers le CDN fonctionnel.
3. Maîtriser les Services DNS (Domain Name System)
Le DNS est le “bottin” de l’Internet. Une panne de DNS peut rendre un site invisible.
- Principe : Ne pas héberger les enregistrements DNS critiques chez un seul fournisseur. C’est d’autant plus vrai s’il s’agit du même fournisseur que l’hébergement ou le CDN.
- Application : Utiliser des services DNS gérés par des prestataires différents et spécialisés (ex: AWS Route 53, Cloudflare DNS, Google Cloud DNS) et configurer une résilience au niveau du bureau d’enregistrement (registrar) pour utiliser plusieurs jeux de serveurs de noms.
4. Renforcer les Tests de Basculement (Failover)
Une stratégie de résilience n’est utile que si elle fonctionne en situation réelle.
- Principe : Réaliser régulièrement des exercices de simulation de panne pour tester les mécanismes de basculement.
- Application : Mener des “Game Days” ou des tests de Chaos Engineering. On simule la défaillance d’un composant (comme la région cloud principale ou le CDN). Cela permet de s’assurer que le basculement vers l’infrastructure de secours est automatique et transparent pour l’utilisateur final.
5. Stratégie de Déploiement Progressif (Canary/Blue-Green)
Les erreurs de configuration sont souvent la cause d’une panne (comme potentiellement celle de Cloudflare).
- Principe : Ne jamais déployer de modifications critiques (mises à jour de configuration ou de code) simultanément sur l’ensemble de l’infrastructure.
- Application : Utiliser des techniques de déploiement progressif (Blue/Green ou Canary) pour appliquer la mise à jour à un petit sous-ensemble de serveurs ou d’utilisateurs d’abord. Si une erreur survient, elle est isolée et peut être rapidement annulée avant qu’elle ne se propage globalement.
Ces mesures représentent un investissement important en temps et en ressources. Toutefois, les experts les considèrent désormais comme une assurance indispensable pour toute entreprise dont la survie dépend d’une présence en ligne constante.
Les dirigeants d’entreprises doivent s’assurer de la résilience de leur infrastructure. L’incendie du 10 mars 2021 chez OVH à Strasbourg avait mis en lumière la conception défaillante de services importants. Même l’Etat français avait eu des sites hors service durant des jours, et des données difficiles à récupérer.
D’autres entreprises ont tout perdu ce jour-là. Et vous ? Si demain AWS disparait, qu’arrive-t-il à vos données ? A vos services ? Votre société continue-t-elle de fonctionner ? Il en va de la survie de votre business.


